从0到1,开始训练你的神经网络
快速开始
面对实际的项目,往往要快速搭建一个可以运行的网络,不要想着精心设计,而是快速迭代优化。训练一个神经网络大概需要三大块内容:数据加载类、神经网络类、损失函数类。基于这些,还可以编写训练函数、评价函数、预测函数,从而训练你的网络,评价模型的好坏,并将预测结果进行可视化。
所以,你有三个思路来完成工作:
- 自顶向下:明确你的优化目标,先完成损失函数,然后设计网络,最后完成数据加载类
- 自底向上:先编写数据加载类,再设计网络,最后设计损失函数;
- 两开花
我的建议是:不管好坏,先制定一个优化目标,然后设计你的神经网络,最后在完成数据加载。
数据加载是个脏活,没什么可说的,我在这里想说一下,如何设计你的网络结构:
- 首先分析问题的复杂程度,来决定如何设计网络;
- 站在前人的肩膀上:参照一个经典的网络进行修改
- 从零开始,自己搭建一个合适的网络。
我认为神经网络的设计是门艺术,没有最好,只有更好。
搭建网络
CNN1
超参数
- 卷积核的大小:
小过滤器收集更多的局部信息:3×3;5×5
大过滤器收集更多的全局信息:9×9;11×11 - padding:保留边界信息,提高性能
- stride:减小图像大小
- channels:特征数,太多可能过拟合
- pooling:下采样,降维
- BN:激活层后,Dropout之后
设计网络的guideline
基本原则:保证特征空间初始阶段宽而浅;而后期窄而深
使用较小的滤波器收集尽可能多的局部信息,然后逐渐增加滤波器的宽度,以减少特征空间的宽度,以代表更多的、全局的、高级的、有代表性的信息
通道数开始时应该很低,这样能检测到低层次的特征,这些低层次的特征合成许多复杂的形状(通过增加通道的数量),有助于区分类别。
增加过滤器的数量以增加特征空间的深度,从而有助于学习更多级别的全局抽象结构。使特征空间更深而窄的另一个办法是缩小特征空间以输入到稠密网络。在神经网络的各层结构中,通道往往会增加或保持不变。
对于中小尺寸图像,使用的卷积核大小通常为3×3、5×5、7×7;最大池化通常为2×2、3×3,步幅为2;较大的卷积核可以将大图像缩小到适当的大小。
如果重视边界信息,请使用same卷积
增加层数,直到过拟合为止。一旦在验证集中获得较高的准确性,采用以下方式来减少过拟合:
L1/L2正则化;Dropout;BatchNorm;数据扩充
设计网络时,以经典网络为灵感。灵感是指结构中的趋势,不是完全的抄袭:
layers:Conv-Pool-Conv-Pool;Conv-Conv-Pool-Conv-Conv-Pool
channels:32–64–128;32–32-64–64
DNN2
超参数
- 层数:
太多:过拟合,梯度消失/爆炸
太少:高偏差,低性能 - 激活函数
- 优化器:SGD容易陷入局部最优;Adam快速收敛
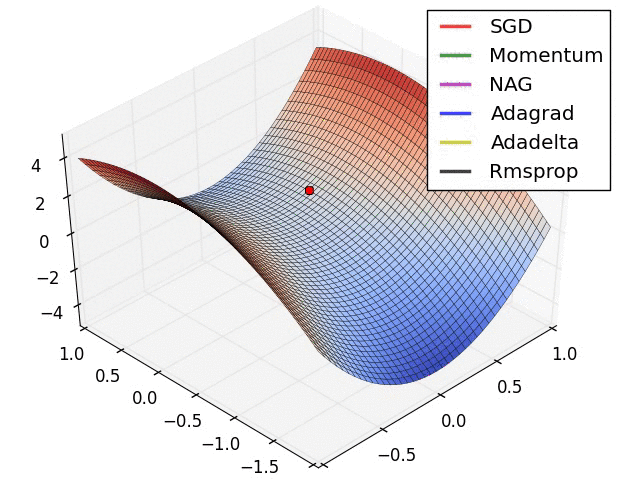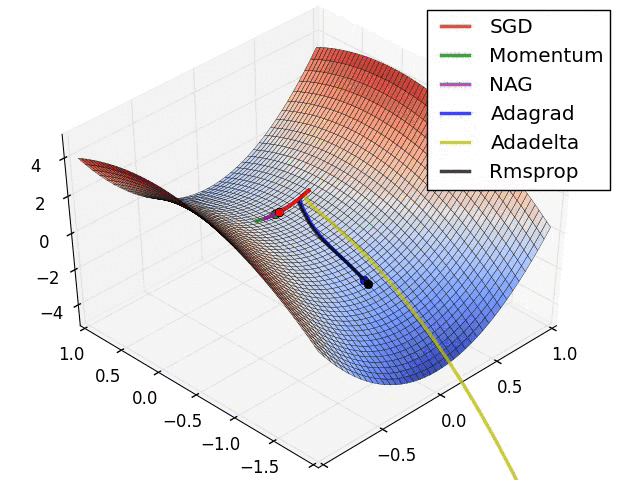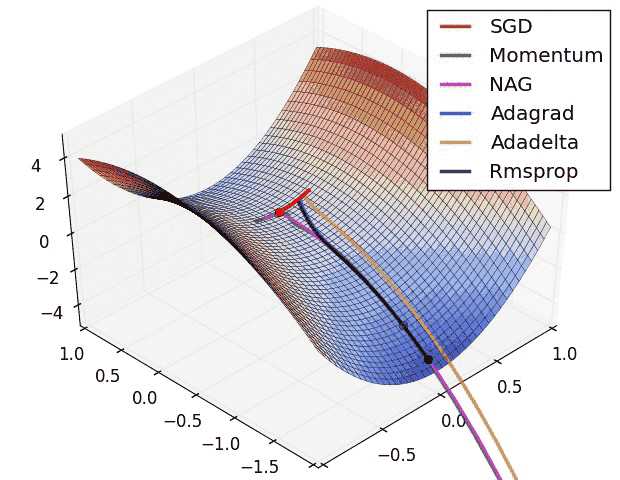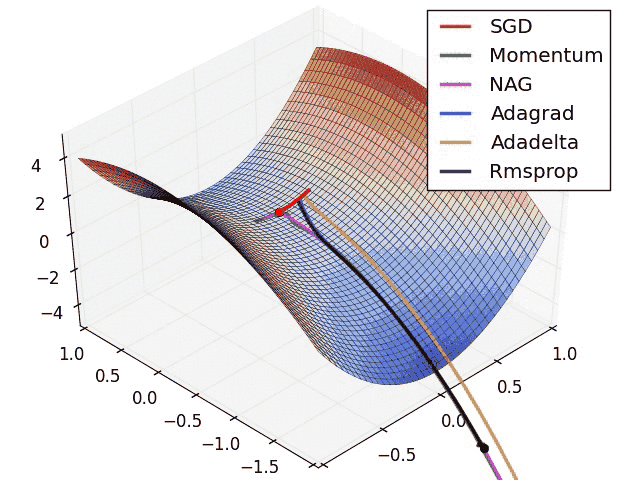
- 学习率:$10^{-n}$
SGD:$10^{-1}$;Adam:$10^{-2}$/$10^{-3}$
learningrate_decay:0.000005或其他 - 初始化:
He-normal/uniform初始化—>ReLU
Glorot-normal/uniform初始化—>Sigmoid - batch_size:$2^{n}$(便于优化内存)
太大:学习缓慢
太小:权重分散 - epochs:
太大:过拟合;泛化问题
太小:限制模型潜力 - Dropout:0~1,通常为0.5。优化偏差方差,解决过拟合
- 正则化(Regularization):以增加偏差的方式减少误差
关于如何设计网络,这里有篇论文:A practical theory for designing very deep convolutional neural networks
训练网络
当按照以上方式完成了三个基本模块之后,就可以训练自己的网络了。
训练时的超参数主要有epochs,batch_size,lr
- epoch:建议前期选小一点,这是为了快速获得训练结果,然后马上推进后面的工作;
- batch_size:选择你电脑性能内的最大值
- lr:根据不同的优化器选择不同的大小
训练时,建议每隔几个epochs就保存一次模型,以便后期进行对比。
调整参数3
这部分是引用别人的,我觉得写的特别好,就保存下来了,话糙理不糙啊.原文的链接在这里
基本原则:快速试错
一些大的注意事项:
1.刚开始, 先上小规模数据, 模型往大了放, 只要不爆显存, 能用256个filter你就别用128个. 直接奔着过拟合去. 没错, 就是训练过拟合网络, 连测试集验证集这些都可以不用.
为什么?
+ 你要验证自己的训练脚本的流程对不对. 这一步小数据量, 生成速度快, 但是所有的脚本都是和未来大规模训练一致的(除了少跑点循环)
+ 如果小数据量下, 你这么粗暴的大网络奔着过拟合去都没效果. 那么, 你要开始反思自己了, 模型的输入输出是不是有问题? 要不要检查自己的代码(永远不要怀疑工具库, 除非你动过代码)? 模型解决的问题定义是不是有问题? 你对应用场景的理解是不是有错? 不要怀疑NN的能力, 不要怀疑NN的能力, 不要怀疑NN的能力. 就我们调参狗能遇到的问题, NN没法拟合的, 这概率是有多小?
+ 你可以不这么做, 但是等你数据准备了两天, 结果发现有问题要重新生成的时候, 你这周时间就酱油了.
2.Loss设计要合理.
+ 一般来说分类就是Softmax, 回归就是L2的loss. 但是要注意loss的错误范围(主要是回归), 你预测一个label是10000的值, 模型输出0, 你算算这loss多大, 这还是单变量的情况下. 一般结果都是nan. 所以不仅仅输入要做normalization, 输出也要这么弄.
+ 多任务情况下, 各loss想法限制在一个量级上, 或者最终限制在一个量级上, 初期可以着重一个任务的loss
3.观察loss胜于观察准确率
准确率虽然是评测指标, 但是训练过程中还是要注意loss的. 你会发现有些情况下, 准确率是突变的, 原来一直是0, 可能保持上千迭代, 然后突然变1. 要是因为这个你提前中断训练了, 只有老天替你惋惜了. 而loss是不会有这么诡异的情况发生的, 毕竟优化目标是loss.
给NN一点时间, 要根据任务留给NN的学习一定空间. 不能说前面一段时间没起色就不管了. 有些情况下就是前面一段时间看不出起色, 然后开始稳定学习.
4.确认分类网络学习充分
分类网络就是学习类别之间的界限. 你会发现, 网络就是慢慢的从类别模糊到类别清晰的. 怎么发现? 看Softmax输出的概率的分布. 如果是二分类, 你会发现, 刚开始的网络预测都是在0.5上下, 很模糊. 随着学习过程, 网络预测会慢慢的移动到0,1这种极值附近. 所以, 如果你的网络预测分布靠中间, 再学习学习.
5.Learning Rate设置合理
+ 太大: loss爆炸, 或者nan
+ 太小: 半天loss没反映(但是, LR需要降低的情况也是这样, 这里可视化网络中间结果, 不是weights, 有效果, 俩者可视化结果是不一样的, 太小的话中间结果有点水波纹或者噪点的样子, 因为filter学习太慢的原因, 试过就会知道很明显)
+ 需要进一步降低了: loss在当前LR下一路降了下来, 但是半天不再降了.
+ 如果有个复杂点的任务, 刚开始, 是需要人肉盯着调LR的. 后面熟悉这个任务网络学习的特性后, 可以扔一边跑去了.
+ 如果上面的Loss设计那块你没法合理, 初始情况下容易爆, 先上一个小LR保证不爆, 等loss降下来了, 再慢慢升LR, 之后当然还会慢慢再降LR, 虽然这很蛋疼.
+ LR在可以工作的最大值下往小收一收, 免得ReLU把神经元弄死了. 当然, 我是个心急的人, 总爱设个大点的.
6.对比训练集和验证集的loss
判断过拟合, 训练是否足够, 是否需要early stop的依据, 这都是中规中矩的原则, 不多说了.
7.清楚receptive field的大小
CV的任务, context window是很重要的. 所以你对自己模型的receptive field的大小要心中有数. 这个对效果的影响还是很显著的. 特别是用FCN, 大目标需要很大的receptive field. 不像有fully connection的网络, 好歹有个fc兜底, 全局信息都有.
简短的注意事项:
- 预处理: -mean/std zero-center就够了, PCA, 白化什么的都用不上. 我个人观点, 反正CNN能学习encoder, PCA用不用其实关系不大, 大不了网络里面自己学习出来一个.
- shuffle, shuffle, shuffle.
- 网络原理的理解最重要, CNN的conv这块, 你得明白sobel算子的边界检测.
- Dropout, Dropout, Dropout(不仅仅可以防止过拟合, 其实这相当于做人力成本最低的Ensemble, 当然, 训练起来会比没有Dropout的要慢一点, 同时网络参数你最好相应加一点, 对, 这会再慢一点).
- CNN更加适合训练回答是否的问题, 如果任务比较复杂, 考虑先用分类任务训练一个模型再finetune.
- 无脑用ReLU(CV领域).
- 无脑用3x3.
- 无脑用xavier.
- LRN一类的, 其实可以不用. 不行可以再拿来试试看.
- filter数量2^n.
- 多尺度的图片输入(或者网络内部利用多尺度下的结果)有很好的提升效果.
- 第一层的filter, 数量不要太少. 否则根本学不出来(底层特征很重要).
- sgd adam 这些选择上, 看你个人选择. 一般对网络不是决定性的. 反正我无脑用sgd + momentum.
- batch normalization我一直没用, 虽然我知道这个很好, 我不用仅仅是因为我懒. 所以要鼓励使用batch normalization.
- 不要完全相信论文里面的东西. 结构什么的觉得可能有效果, 可以拿去试试.
- 你有95%概率不会使用超过40层的模型.
- shortcut的联接是有作用的.
- 暴力调参最可取, 毕竟, 自己的生命最重要. 你调完这个模型说不定过两天这模型就扔掉了.
- 机器, 机器, 机器.
- Google的inception论文, 结构要好好看看.
- 一些传统的方法, 要稍微了解了解. 我自己的程序就用过1x14的手写filter, 写过之后你看看inception里面的1x7, 7x1 就会会心一笑…
优化模型
当模型已经很好的拟合结果,甚至是过拟合时,就可以考虑优化了.跟快速开始中一样,仍然有三个部分可以优化.
但在优化之前,你必须完成你的评价函数了,你需要一个合理的评价指标,你的目的就是尽量在这个指标下做到最好.
数据
从数据下手是优化模型的灵丹妙药,但是人力成本就很高了,最优的方案当然是扩充你的数据集,使样本空间更大.如果做不到这些,或者是你的数据集已经很庞大了,那这将收效甚微.可以考虑用代码的方式进行数据扩增(data augmentation):翻转,旋转,裁剪等.这样可以成倍地扩充数据集.具体如何扩增,请对实际问题进行分析.
网络
如果效果已经很好了,就不需要再增加层数了,这样只会徒增参数,起不到什么效果.可以考虑的是:在网络的开始几层添加BatchNorm,不需要太多,这样可以加速收敛.如果过拟合了,可以在最后几层使用Dropout.对于优化网络,我的心得还不是很多.
损失函数
损失函数放在最后,我认为这是最不该优化的地方,因为这是你最初设计网络,训练模型一直想要逼近的目标,如果你修改了损失函数,甚至是大改特改,推倒重来,那这将意味着你之前做的努力都付之东流了
神经网络可以解决什么问题4
这是我做完项目之后的反思,神经网络究竟能干什么,它的极限在哪里,它不能解决什么,这有待以后的深入学习.
经过我查阅了大量博客,没有找到相关的论文(肯定有这方面的论文,只是我没找到)
神经网络目前主要可以解决(预测)两类问题:
- 分类问题(Classification)(离散问题)
- 回归问题(Regression)(连续问题)
比如手写数字识别就是一个典型的分类问题,体重预测是一个典型的回归问题.而一些比较复杂的情景我认为就是既有分类问题,也有回归问题.比如说目标识别中,定位目标是一个回归问题,检测目标是什么类别是一个分类问题.
当你分析清楚实际问题到底是哪类问题时,就可以采用不同的策略.
具体什么策略我还没有研究.
1. A guide to an efficient way to build neural network architectures- Part II: Hyper-parameter selection and tuning for Convolutional Neural Networks using Hyperas on Fashion-MNIST ↩
2. A guide to an efficient way to build neural network architectures- Part I: Hyper-parameter selection and tuning for Dense Networks using Hyperas on Fashion-MNIST ↩
3. 卷积神经网络的卷积核大小、个数,卷积层数如何确定呢? ↩
4. 深度学习 分类问题与回归问题 ↩