目标定位
如何定位图片中对象的位置?
目标的参数化表示,让神经网络多输出4个单元:- $b_{x}$:边界框的中心点的x坐标
- $b_{y}$:边界框的中心点的y坐标
- $b_{h}$:边界框的高度
- $b_{w}$:边界框的宽度
如何为监督学习任务定义目标标签$y$?
- $p_{c}$:表示是否存在目标;使用逻辑回归
- $b_{x},b_{y},b_{h},b_{w}$:边界框参数;
- $c_{1},c_{2},c_{3}$:不同类别;使用softmax,甚至是均方误差。
$p_{c}=1$时,表示图中存在目标对象;
$p_{c}=0$时,表示图中不存在目标对象,其余参数无意义。
特征点检测
假设构建一个人脸特征点检测的神经网络,检测人脸的64个关键点,则神经网络的最后一层需要输出129个单元:每个点的坐标为$(x,y)$,一共需要128个单元,还需要一个单元来确定是否存在人脸,所以一共需要129个单元。
目标检测
基于滑动窗口的目标检测算法。
- 构建标签训练集,训练卷积网络,然后利用其实现滑动窗口实现目标检测:
- 选定一个特定大小的窗口,将其中的部分图像输入网络,判断是否存在目标;
- 使用这个窗口遍历整张图片(这个过程有些类似于过滤器卷积输入图像),对每个位置进行分类;
- 选用更大的窗口重复以上步骤,肯定会有一个窗口可以检测到目标。
缺点:
- 小步幅窗口多,性能较好,但计算成本太大;
- 大步幅窗口少,性能差,计算成本相对低。
滑动窗口的卷积实现
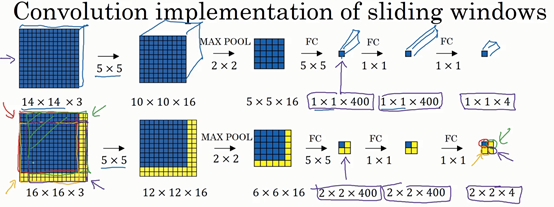
使用卷积可以实现计算共享,提高性能。
上图中,14×14×3的蓝色矩阵代表输入训练集,经过神经网络的训练,可以得到一个1×1×4的分类结果;
16×16×3代表在测试集上进行抽象的滑动窗口,这里并没有真的滑动窗口,而是整个图片进行卷积计算后,2×2的预测结果正好可以与模拟的四次滑动窗口进行映射,这样,利用卷积计算,一次性的实现了整张图片的滑动窗口检测。其中,MAX POOL的维度可以控制抽象滑动窗口的步长。
Bounding Box预测
滑动窗口的卷积实现效率较高,但不能获得最精准的边界框,为了得到更精准的边界框,采用Bounding Box预测
此算法相当于将原图像进行了裁剪,并对每个小子图进行标注。例如裁剪为3×3的图像后,要对九个子图都进行标注,并当作训练数据,训练整个网络
交并比
评价对象检测算法。

$IoU>0.5$时,可以采用。这个0.5是人为规定的,如果需要提高对算法的要求,可以规定更大的$IoU$
非极大值抑制
非极大值抑制可以确保算法对每个对象只检测一次
- 去掉概率低于某个阈值的边框
- 选择概率最大的边框,去掉与概率最大的边框交并比较大的边框
Anchor Boxes
到目前为止,对象检测中存在的一个问题是每个格子只能检测出一个对象,如果你想让一个格子检测出多个对象,就是用Anchor Boxes。
预先定义两个不同形状的anchor box,或者anchor box形状,把预测结果和这两个anchor box关联起来。
定义类别标签,不使用:
而是重复两次,使用:
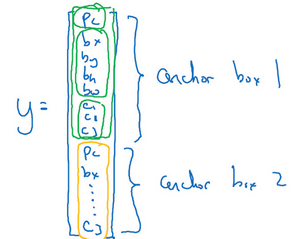
前8个参数和anchor box 1关联,后8个参数和anchor box 2关联